本如何碾压一代语言I的新模型力长文超能
说真的,作为一个长期关注AI发展的业内人士,我不得不感叹Meta这次放了个大招。还记得去年OpenAI的GPT-3.5-Turbo-16k惊艳亮相时,我们都觉得这已经是自然语言处理的巅峰之作。但科技就是这样,永远在给我们惊喜。一场悄悄进行的"技术革命"Meta的工程师们这次玩了个聪明的把戏。他们没有另起炉灶,而是在现有的LLAMA2基础上进行了"升级改造"——就像给一辆跑车换上更强劲的发动机。最让...
说真的,作为一个长期关注AI发展的业内人士,我不得不感叹Meta这次放了个大招。还记得去年OpenAI的GPT-3.5-Turbo-16k惊艳亮相时,我们都觉得这已经是自然语言处理的巅峰之作。但科技就是这样,永远在给我们惊喜。
一场悄悄进行的"技术革命"
Meta的工程师们这次玩了个聪明的把戏。他们没有另起炉灶,而是在现有的LLAMA2基础上进行了"升级改造"——就像给一辆跑车换上更强劲的发动机。最让我惊讶的是他们用了4000亿个token的训练数据,这个数字简直疯狂!想象一下,这相当于把整个维基百科的内容重复学习了上百遍。
两大"杀手锏"模型
研究团队非常务实,他们设计了两种不同规格的模型:
一个是"轻量级选手"——7B/13B参数规模的模型,相当于给小型企业准备的"经济适用型"解决方案;另一个则是"重量级选手"——34B/70B参数规模的大模型,专为处理更复杂的任务而生。
有意思的是,我发现他们在设计训练序列时特别注重实用性。32,768和16,384这样的token长度设置,明显是经过深思熟虑的——既保证了性能,又不会让计算成本高得离谱。
不只是长文本那么简单
在实际测试中,这些模型的表现简直让人眼前一亮。特别是在编码和数学推理任务上,进步幅度之大让我这个"老AI人"都感到惊讶。举个例子,在处理一段复杂的编程问题时,新模型能更好地理解上下文关系,就像一个有经验的程序员在阅读同事的代码。
最妙的是他们的指令微调方法。传统的微调需要大量人工标注数据,成本高得吓人。但Meta找到了一个更聪明的办法——不需要人类手动标注,这为公司节省了多少预算啊!
超越GPT-3.5意味着什么?
当我看到测试结果时,不禁笑出了声。谁能想到开源社区这么快就能超越商业巨头的标杆产品?这不仅是个技术突破,更是个商业模式的胜利。
不过作为业内人士,我也要泼点冷水。这些模型在处理超长文档时还是会出现"记忆模糊"的情况,就像人类看一本厚厚的专业书籍时也会偶尔走神。但这已经是个了不起的进步了!
未来的想象空间
看着这些进展,我不禁开始畅想:未来的客服系统会不会像《钢铁侠》里的贾维斯一样贴心?法律文书自动生成会不会比资深律师还靠谱?这些曾经只存在于科幻电影的场景,正在一步步变成现实。
当然,技术永远没有终点。我期待着Meta和整个AI社区能带来更多惊喜。毕竟在这个领域,今天的"不可能"很可能就是明天的"基本配置"。
- 黄金市场观察:多头行情能否持续?资深交易员为您解析2025-09-15 06:54
- 赵秦川:市场共识已现,双十一黄金买点不容错过2025-09-15 06:40
- 揭秘中国顶尖咨询公司的崛起密码:一家本土企业的逆袭之路2025-09-15 06:18
- 当比特币变成数字画布:一场背离初衷的资本狂欢2025-09-15 05:23
相关阅读
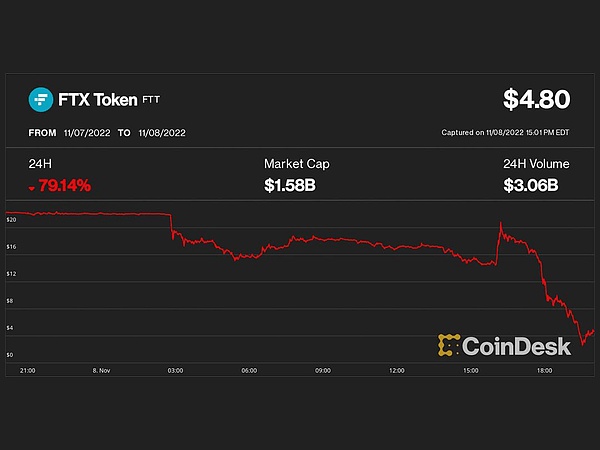
8.25数字货币市场观察:比特币遇阻回落 以太坊创高后跳水
最近在复盘行情时,我常想起一句话:交易就像种地,播种时就要想好收获的季节。说实话,现在的市场波动确实让人心跳加速,特别是以太坊刚创下历史新高就来了个"深蹲",这到底是主力洗盘还是行情见顶?让我们一起来分析分析。比特币技术面解析从日线来看,比特币就像个犹豫的登山者,在中轨附近来回踱步。周线连续收阴,把价格压到了7日均线下方,这不,今天开盘就直奔下轨而去。布林带微微张开嘴,MACD指标也一副要"下山"...
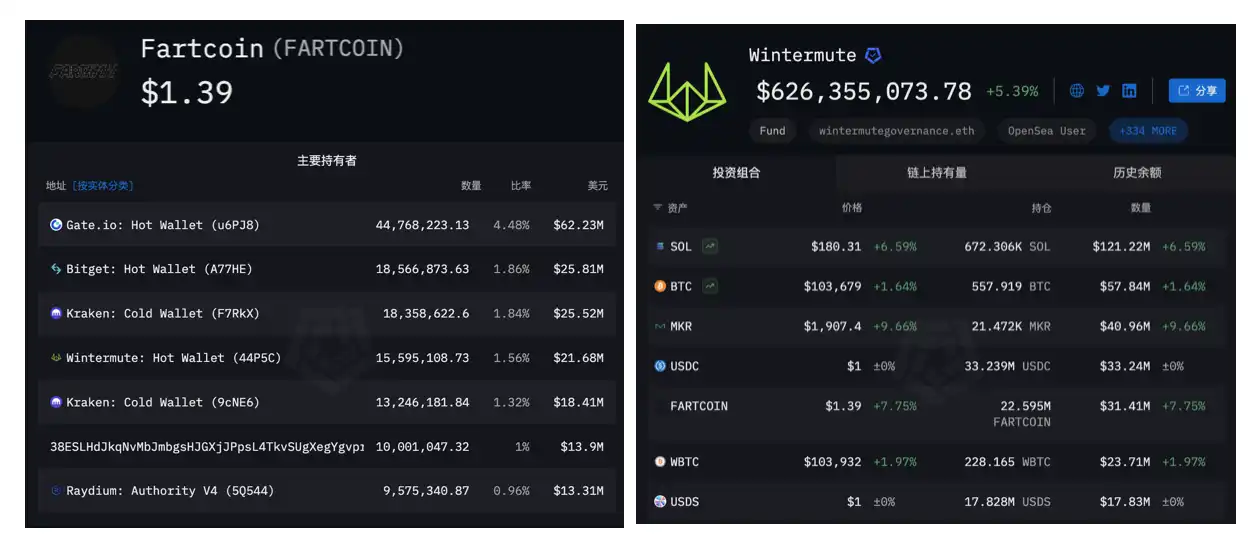
旅游业迎来重大利好:文旅部推动景区REITs创新融资
最近文旅部放大招了!我在"REITs50人论坛"看到11月13日发布的重磅消息,为落实国务院关于旅游业高质量发展的工作部署,文旅部专门制定了《国内旅游提升计划(2023-2025年)》。作为一个经常关注文旅行业的老司机,我觉得这份计划来得正是时候。说实话,这些年旅游业过得真不容易。文旅部这次明确提出,到2025年要让国内旅游市场不仅规模增长,更要品质升级。重点是要让游客体验更好、满意度更高,同时完...

OpenAI董事会戏剧性反转:CEO离职风波背后的权力游戏
这可能是硅谷历史上最戏剧性的24小时之一。就在昨天,OpenAI董事会以"缺乏坦诚"为由突然解雇了CEO山姆·奥特曼,而今天他们竟然又低声下气地求他回来!这波操作简直比美剧还精彩,让我这个看惯了科技圈风云变幻的老记者都直呼内行。资本的力量:投资人震怒引发大反转说实话,当我看到微软CEO萨蒂亚·纳德拉得知奥特曼离职后"怒发冲冠"的报道时,就预感会有反转。毕竟微软可是持有OpenAI 49%股份的大金...

那些年,他们押注比特币的疯狂赌局
在加密货币的世界里,总有一些让人热血沸腾的暴富传奇。作为长期观察这个市场的金融从业者,我见证过太多人的命运在此改写。今天就给大家讲讲几个让我印象深刻的真实故事,这些普通人用智慧和勇气,在比特币浪潮中实现了财富自由。1. 从交易新手到宾利车主记得2018年市场低迷时,Javed Khan还只是个普通的交易员。当时比特币价格在3000美元左右徘徊,很多人避之不及,他却把比特币转账当成了副业。我至今记得...

XRP律师揭秘:纽约监管风波背后的真相
作为一名长期关注加密货币市场的从业者,最近纽约金融服务部(DFS)的动作让我不禁皱眉。约翰·迪顿这位在Ripple与SEC官司中代表7.5万名XRP持有者的知名律师,向我们透露了一些内幕消息。说实话,当我看到XRP和狗狗币突然从纽约的"绿名单"上消失时,第一反应就是:又来?监管风暴来袭纽约DFS这次的动作可不小,一下子把25种加密货币从"绿名单"上除名。要知道这个名单相当于纽约版的"监管通行证",...
加密周报:美国政坛为比特币撑腰,华尔街大鳄纷纷押注
这周区块链圈子的新闻真是让人眼前一亮。要说最振奋人心的,莫过于美国政界终于有人站出来为加密货币说话了。让我们来看看这个行业的精彩故事。政界大佬为加密资产发声Ted Budd这位美国参议员可真是给力,他提出的"Keep Your Coins Act"法案简直就像是给加密货币爱好者的一剂强心针。要知道,在FTX暴雷事件后,很多人对第三方托管机构都心有余悸。这位参议员说得很实在:"当消费者面临数字货币带...